自然語言處理可視化(NLP visualization)
目錄
前言
目的
為了在祐生基金會報告Text Analytics with Python: A Practical Real-World Approach to Gaining Actionable Insights from your Data,實作了一遍書中介紹的各種NLP操作,並將結果以視覺化的圖表呈現。由於原作者已經提供了完整程式碼,這裡就只簡單記錄一些結果。重點在呈現有哪些可視化操作,而不是具體的程式碼。
補記:這本書2019年出了第二版,內容大致上差不多,主要的區別是:
- 舊版使用Python 2,新版使用Python 3
- 新版增加了一個章節講深度學習
- 新版提到比較多可視化的工具
主要工具
NLTKscikit-learnspaCygensimfastHanscattertextbokeh
文本來源
祐生基金會的例行活動公開紀錄文,包含 國政聯誼會 57篇及 見識之旅 44篇,兩種文類合計 101 篇。文本包含中文原文及英文譯文。
- 按文章分類,共101筆資料
文本預處理
- 中文斷詞跟NER都使用
fastHan,斷詞風格依據中研院as - 英文斷詞跟NER都使用
spaCy
靜態可視化
依據中文文本
-
文本類別分佈:使用PCA將文本向量降至2維,這裡的類別是文本實際的類別(
國政聯誼會= Meeting,見識之旅= Trip)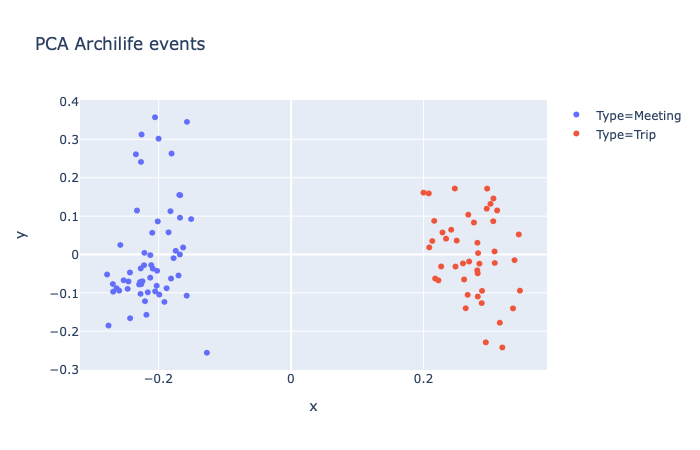
-
文本聚類分佈:使用Kmeans計算文本向量之間的距離,預先設定2個聚類中心,這裡的類別是根據Kmeans計算出來的類別(即
0或1)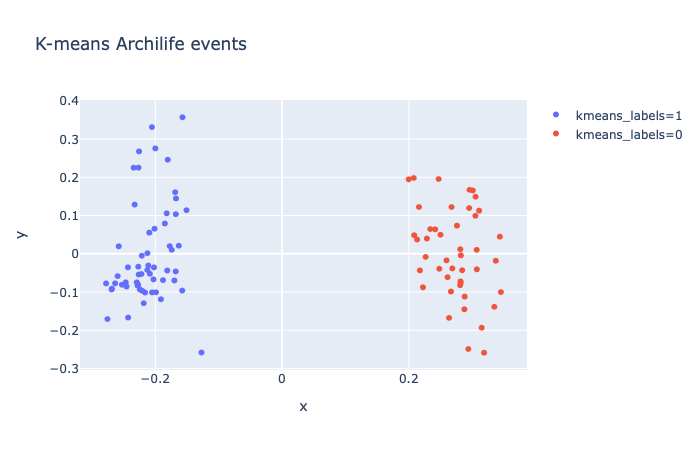
-
文本相似度:使用餘弦相似性計算語料庫內的文本相似度,樹狀圖末梢標示文本事件的年、月以及文本類型(
國政聯誼會= M,見識之旅= T)
-
句子相似度:使用餘弦相似性計算單一文本內的句子相似度,每個節點代表一個句子(共
16)。後續導入TextRank,設定句子數量(例如5)後即獲得文本摘要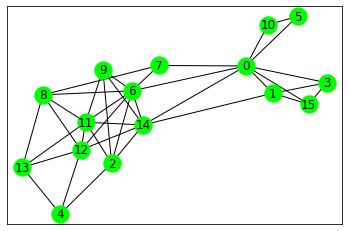
- 原始文本
9月份見識之旅活動,於2019年9月21日由呂明澐小姐帶領12位祐生見習生及其家長們,進行桃園侏儸紀寶石教室暨防災教育體驗之旅。活動開始之初,領隊呂明澐小姐提醒本次活動注意事項及觀察重點,先行建立見習生的背景知識。 本次行程上午至德馨堂參訪,由當地發展協會志工擔任導覽老師。活動一開始即介紹該建築座東向西,風水上有聚財之意,俚語稱「座東向西,賺錢無人知」。隨後說明德馨堂為燕尾式閩南傳統民居,在古代認為鳥是通天靈物,能敬天通神,故燕尾翹脊多見於廟宇或官宅,由此可知其祖先當時有官職在身。緊接著前往侏儸紀博物館。導覽人員首先解說寶石生成的環境要件及各式寶石的特徵和產地,其中紅色尖晶石與紅剛玉外觀相似,過去常被誤認,英國皇家王冠上的黑王子紅寶石後被證實為紅色尖晶石即案例之一。接著觀賞寶石開採紀錄片,內容記述寶石礦坑的真實樣貌。礦工須下爬約台北101大樓高的距離至地底採礦,礦坑內部粉塵飛揚、工作環境惡劣,炸礦脈也易發生坍塌,故駐紮地底的礦工平均壽命不超過35歲,值得我們反思貧富差距的問題。影片播畢後,導覽人員教導簡易的琥珀鑑定方法—將琥珀放進飽和鹽水中,因其相對密度較小,會懸浮於飽和鹽水中。 中午飯後,前往桃園防災教育館。導覽人員藉由互動式模型解釋颱風、地震及土石流等天災發生的成因。其中特別說明地震發生時,人們會因地震波的傳播感受到搖晃,地震波主要有破壞力較小的P波與破壞力較大的S波,目前地震警報即透過最先抵達的P波預估S波之振動大小,並在S波抵達前發出警報,爭取數秒的預警時間。隨後至火災防治區,火災發生原因可分為四類,不同類型的火災須採取不同滅火方式,避免造成更大的危害,眾人亦於濃煙密布的房間演練火災發生時如何逃生。參訪當天為921大地震20周年,導覽人員特別提醒地震避難時應記住「趴下」、「掩護」、「穩住」三大步驟,找到適當躲避地點後應以雙手護住頭及頸椎趴跪於地面,隨即於地震體驗平台實地練習,以備往後地震避難時之需。至此,本日活動已近尾聲,大家一起合照留念後搭車返程,並期待於下次見識之旅再相見。
- 摘要文本
9月份見識之旅活動,於2019年9月21日由呂明澐小姐帶領12位祐生見習生及其家長們,進行桃園侏儸紀寶石教室暨防災教育體驗之旅。活動開始之初,領隊呂明澐小姐提醒本次活動注意事項及觀察重點,先行建立見習生的背景知識。導覽人員首先解說寶石生成的環境要件及各式寶石的特徵和產地,其中紅色尖晶石與紅剛玉外觀相似,過去常被誤認,英國皇家王冠上的黑王子紅寶石後被證實為紅色尖晶石即案例之一。導覽人員藉由互動式模型解釋颱風、地震及土石流等天災發生的成因。參訪當天為921大地震20周年,導覽人員特別提醒地震避難時應記住「趴下」、「掩護」、「穩住」三大步驟,找到適當躲避地點後應以雙手護住頭及頸椎趴跪於地面,隨即於地震體驗平台實地練習,以備往後地震避難時之需。
- 原始文本
後記:後來發現有textrank4zh 這個套件,專門處理中文摘要。使用TextRank需要事先斷句、斷詞,而textrank4zh 的好處是直接餵入原始文本,就能獲得關鍵詞、關鍵短語、摘要。例如:
import textrank4zh
from textrank4zh import TextRank4Keyword, TextRank4Sentence
tr4w = TextRank4Keyword()
tr4w.analyze(text=text, lower=True, window=2)
print( '關鍵詞:' )
for item in tr4w.get_keywords(20, word_min_len=1):
print(item.word, item.weight)
print('='*20)
print( '關鍵短語:' )
for phrase in tr4w.get_keyphrases(keywords_num=20, min_occur_num=1):
print(phrase)
tr4s = TextRank4Sentence()
tr4s.analyze(text=text, lower=True, source = 'all_filters')
print('='*20)
print( '摘要:' )
for item in tr4s.get_key_sentences(num=5):
print(item.index, item.weight, item.sentence)
這裡的text就是上面的9月份見識之旅,執行之後得到:
關鍵詞:
後 0.027962039363435023
地震 0.022010169581731007
於 0.014880799653226645
發生 0.013589951544039922
寶石 0.013551887178181725
導覽 0.010060511434570879
火災 0.009771097997533784
波 0.00949178439970326
時 0.009116332003172464
見 0.008749194133705994
人員 0.008166338970883414
見識 0.007826782749554022
桃園 0.007740704753034728
前往 0.00760413864186173
地底 0.007568837029280538
活動 0.007468707396160205
體驗 0.00739460652918148
環境 0.0070961613242429295
紀 0.006957075437160697
錢 0.0069192172065872665
====================
關鍵短語:
導覽人員
火災發生
於地震體驗
後地震
地震發生時
火災發生時
====================
摘要:
14 0.09016204400462761 參訪當天為921大地震20周年,導覽人員特別提醒地震避難時應記住「趴下」、「掩護」、「穩住」三大步驟,找到適當躲避地點後應以雙手護住頭及頸椎趴跪於地面,隨即於地震體驗平台實地練習,以備往後地震避難時之需
0 0.07976884824618512 9月份見識之旅活動,於2019年9月21日由呂明澐小姐帶領12位祐生見習生及其家長們,進行桃園侏儸紀寶石教室暨防災教育體驗之旅
6 0.07576174585612215 導覽人員首先解說寶石生成的環境要件及各式寶石的特徵和產地,其中紅色尖晶石與紅剛玉外觀相似,過去常被誤認,英國皇家王冠上的黑王子紅寶石後被證實為紅色尖晶石即案例之一
9 0.07008120311442011 影片播畢後,導覽人員教導簡易的琥珀鑑定方法—將琥珀放進飽和鹽水中,因其相對密度較小,會懸浮於飽和鹽水中
13 0.06998434006205283 隨後至火災防治區,火災發生原因可分為四類,不同類型的火災須採取不同滅火方式,避免造成更大的危害,眾人亦於濃煙密布的房間演練火災發生時如何逃生
以相同的文件來說,TextRank的摘要結果比textrank4zh 還要好,前者抓到了事件的起承轉合,後者則是拘泥於事件的細節。導致兩者差異的原因留待日後進一步了解。
依據英文文本
-
文本類別分佈(2D):將文本向量的特徵限縮至2個,顏色代表文本的實際類別
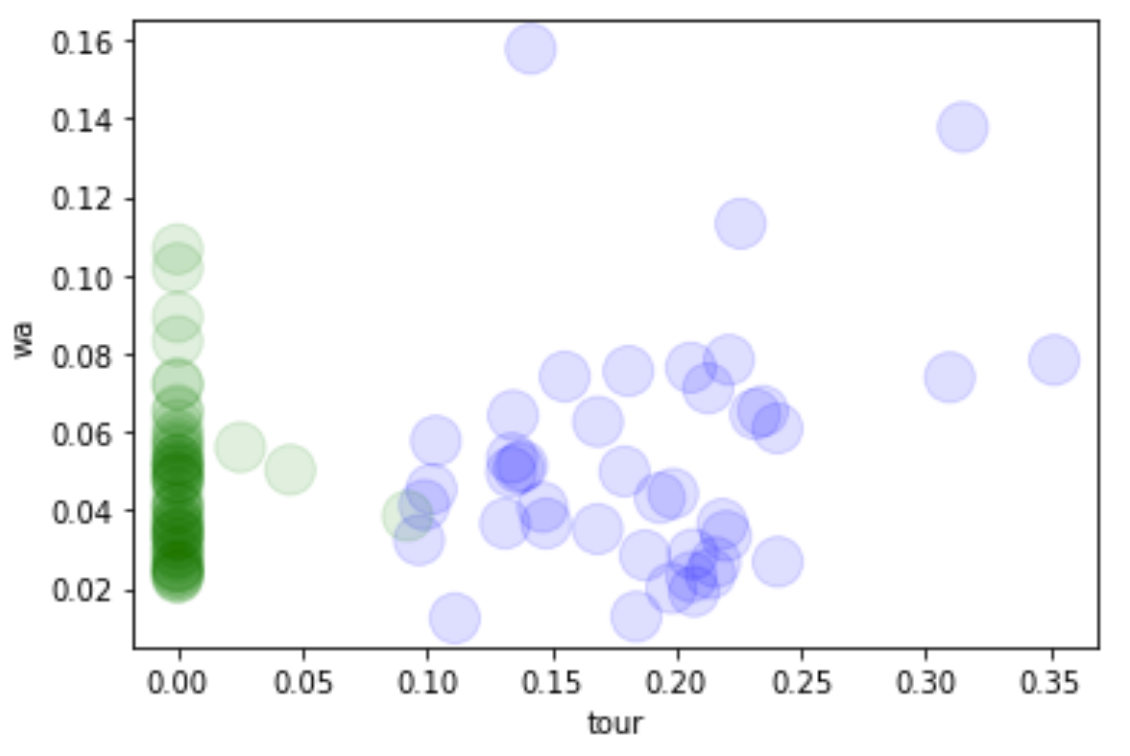
-
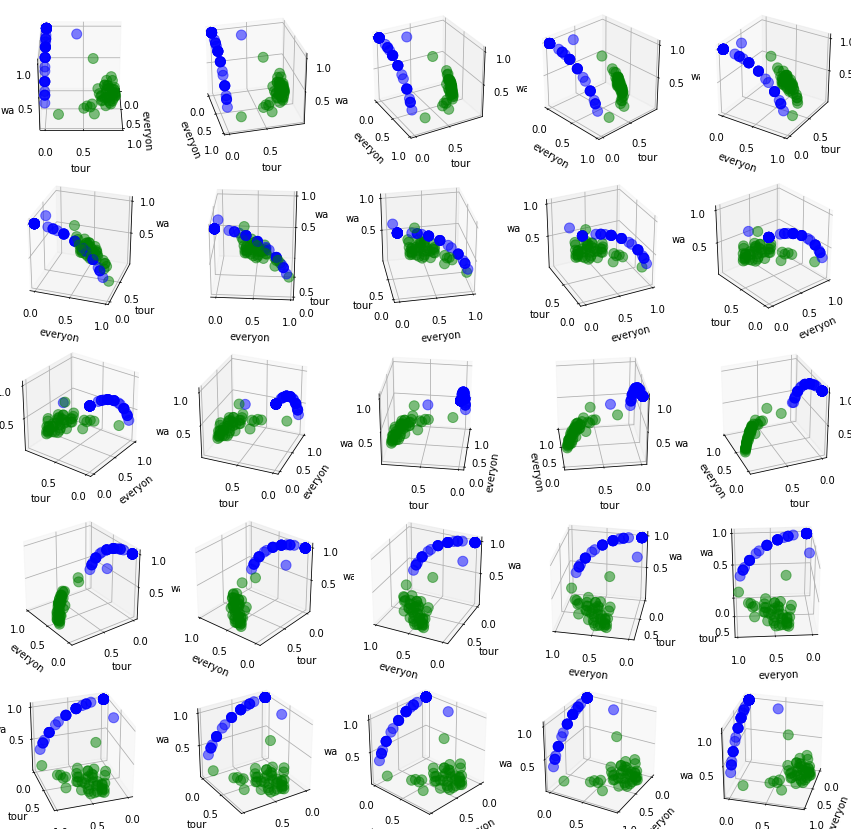
文本類別分佈(3D):將文本向量的特徵限縮至3個,顏色代表文本的實際類別,呈現25種角度
動態可視化
點選圖表另開視窗,就可以跟文本互動囉! :wink:
依據中文文本
- 所有詞 - 文類1 vs. 文類2
- 所有詞 - 特徵詞 vs. 文類
- 命名實體詞 - 文類1 vs. 文類2
- 命名實體詞 - 特徵詞 vs. 文類
- 前1000高頻詞,PCA降階 - 用
gensim的Word2Vec模型訓練文本,獲得32階的向量,取高頻的前1000詞,再用PCA降階之後用bokeh繪圖。
具體設定如下:
from gensim.models import Word2Vec
from sklearn.decomposition import PCA
from sklearn import preprocessing
import numpy as np
model = Word2Vec(data_tok,
size=32, # 設定維度
min_count=5, # 限制最低詞頻
window=5).wv # 訓練視窗
words = sorted(model.vocab.keys(),
key=lambda word: model.vocab[word].count,
reverse=True)[:1000] #取前10000高頻詞
word_vectors = np.array([model.get_vector(w) for w in words]) #將10000詞轉向量
# 確定參數格式正確
assert isinstance(word_vectors, np.ndarray)
assert word_vectors.shape == (len(words), 32) #10000詞,每個詞32階
assert np.isfinite(word_vectors).all()
pca = PCA(n_components=2) #降至2階
word_vectors_pca = pca.fit_transform(word_vectors)
preprocessing.scale(word_vectors_pca) #標準化,達到zero mean跟unit variance
#拿著word_vectors_pca[:, 0]、word_vectors_pca[:, 1]跟words這三個參數就可以繪圖了!
-
前1000高頻詞,t-SNE降階 - 用
gensim的Word2Vec模型訓練文本,獲得32階的向量,取高頻的前1000詞,再用t-SNE降階之後用bokeh繪圖。
設定跟上面一樣,只是把PCA換成t-SNE,具體程式碼如下:
from sklearn.manifold import TSNE
import time
time_start = time.time()
tsne = TSNE(n_components=2, verbose=1, perplexity=40, n_iter=300) #降至2階
word_vectors_tsne = tsne.fit_transform(word_vectors)
print('t-SNE done! Time elapsed: {} seconds'.format(time.time()-time_start))
運行結果為:
[t-SNE] Computing 121 nearest neighbors...
[t-SNE] Indexed 1000 samples in 0.004s...
[t-SNE] Computed neighbors for 1000 samples in 0.074s...
[t-SNE] Computed conditional probabilities for sample 1000 / 1000
[t-SNE] Mean sigma: 0.043001
[t-SNE] KL divergence after 250 iterations with early exaggeration: 50.374985
[t-SNE] KL divergence after 300 iterations: 0.505594
t-SNE done! Time elapsed: 8.125535249710083 seconds
同樣將word_vectors_tsne標準化之後,拿著word_vectors_tsne[:, 0]、word_vectors_tsne[:, 1]跟words這三個參數就可以繪圖了!
依據英文文本
- 所有詞 - 文類1 vs. 文類2
- 所有詞 - 特徵詞 vs. 文類
- 命名實體詞 - 文類1 vs. 文類2
- 命名實體詞 - 特徵詞 vs. 文類
- 主題 - 文類1 vs. 文類2
- 文本相似度 - TF-IDF詞嵌入
